多源的数据集成将不同业务系统中分散、零乱、标准不统一的各种源数据中的数据进行汇聚。支持从DBMS、互联网、物联网、企业生产系统等各种数据源中提取数据。各类数据经过抽取、清洗和转化后,实现多对多地加载到包含但不限于大数据集群和各类关系型数据库中。该过程由一个统一的操作接口封装,经过无代码的可视化配置后,可实现自动化地、分布式地执行整个ETL作业流程。
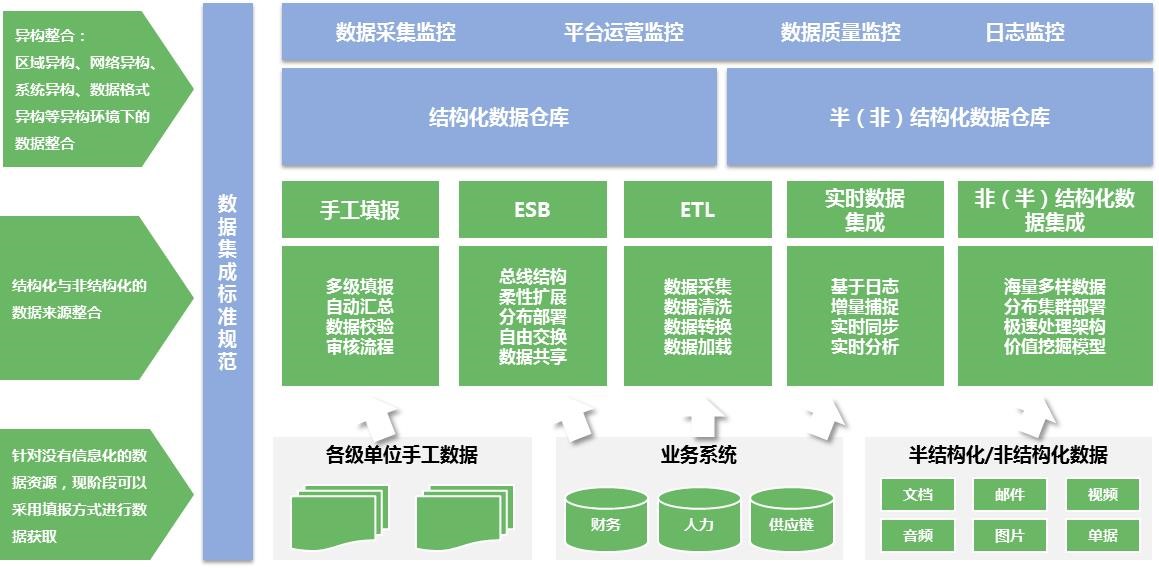
涵盖企业从数据定义、采集、存储、整合交换、分析计算与决策支持直到业务归档进入历史数据的生命周期的各个阶段

1、 先进的融合计算架构
采用Hadoop和MPP融合技术架构,对半结构化、非结构化数据提供低成本存储,并提供低时延、高并发的查询和分析功能;对结构化数据采用MPP分布式数据库,支持列式存储、分布式计算、智能索引等功能,实现高性能结构化数据分析处理。集成MapReduce、Spark、Storm、Tez等多种计算引擎,利用YARN资源管理组件统一管理调度,可在同一份数据集上运行多种计算引擎,能满足高吞吐、大数据量和低时延实时处理等多方面的数据计算要求。
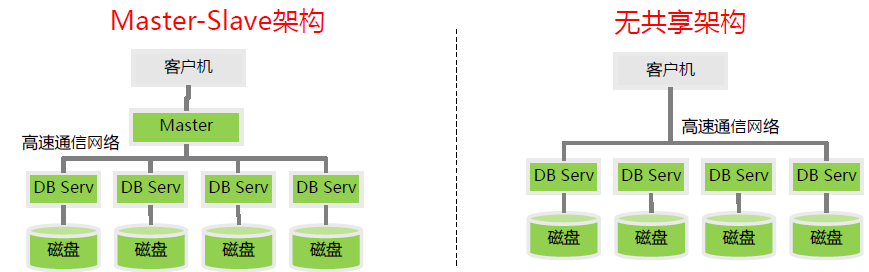
2、 高性价比的分布式集群
基于x86服务器本地的计算与存储资源,计算集群可以动态调整,从数台到数千台之间弹性扩展,按需构建应用,减少总体成本;同时,在设计时充分考虑了硬件设备的不可靠因素,在软件层面提供计算和存储的高可靠保证,具备较强的容错性。
3、 数据分层和分级存储
把数据按照不同阶段分为ODS(Operational Data Store)数据、轻度汇总数据、和应用数据,分别存储在关系型数据库、Hadoop平台、MPP分布式数据库,满足不同阶段的计算需求;按照在线数据、历史数据等来管理数据生命周期,满足在线数据的高性能存储的需求;将核心模型数据通过改造融入到数据仓库的核心模型中,减少数据冗余,提升数据质量。
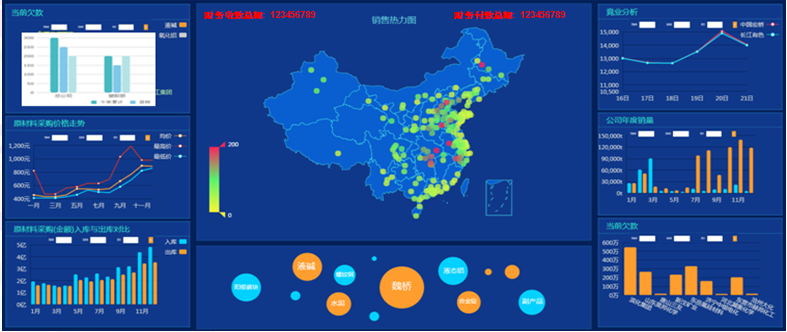
产品提供丰富的图表类型以及酷炫的前端界面,支持可视化自由组合
1、 分析组件
提供图表组件,文本组件以及查询控件和按钮,用户可以自由地将组件拖拽到dashboard画布中,进行分析。
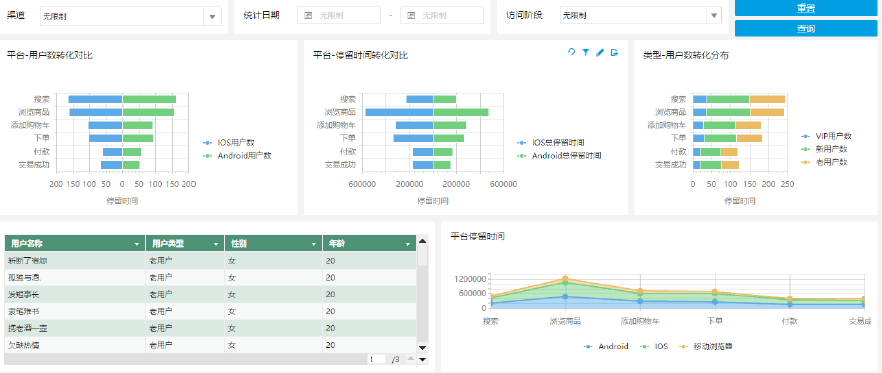
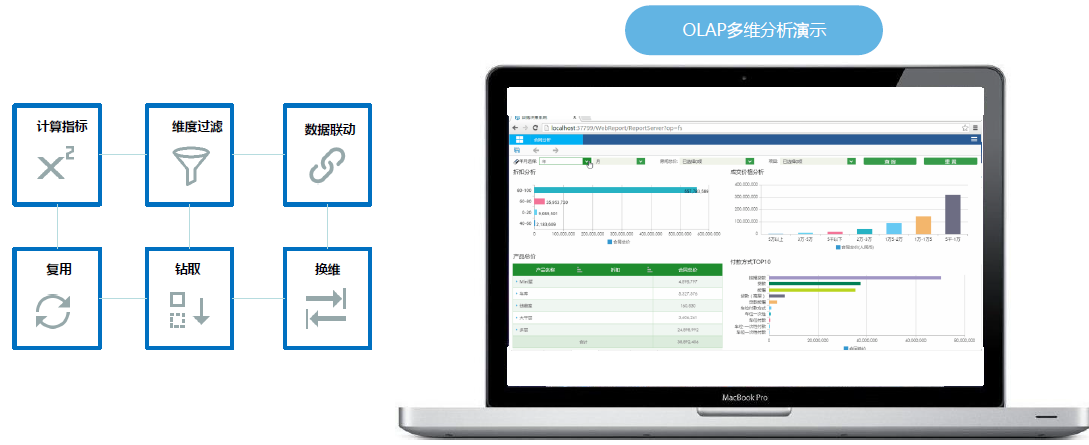
2、 自助多维分析
在使用处理好的数据进行多维分析时,用户可以自由根据业务需要,变换维度进行分析。包括添加计算指标,联动,钻取,过滤,复用,预警等。

3、 自动建模
通过自动建模,便捷的进行探索性分析
4、 数据可视化定制
可定制化大屏展示